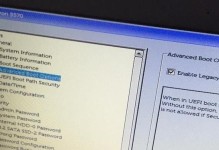
在日常生活和工作中,我们经常会遇到需要从图片中提取文字的需求,例如从扫描文件中提取文字内容、从网上下载的图片中提取文字等。传统的方法是手动输入或者复制粘贴,但这样效率低下且容易出错。本文将介绍如何利用电脑快速提取图片中的文字,帮助读者提高工作效率。

选择合适的OCR软件
安装和配置OCR软件
导入待处理的图片文件
调整图片设置以优化识别效果
选择识别语言和输出格式
启动OCR识别过程
处理批量图片文件
手动校正识别错误
应用OCR结果到不同场景
调整OCR识别参数以提高准确性
识别多页PDF文件中的文字
使用OCRAPI实现自动化文字提取
注意OCR的局限性和限制条件
备份和保存OCR识别结果
常见问题解答
选择合适的OCR软件:根据个人需求和预算选择一款适合自己的OCR软件,如AdobeAcrobat、ABBYYFineReader、Tesseract等。
安装和配置OCR软件:下载并安装选择的OCR软件,并按照软件的指引进行配置和设置,以确保软件可以正常运行。
导入待处理的图片文件:将需要提取文字的图片文件导入到OCR软件中,可以通过拖拽、选择文件或者批量导入的方式实现。
调整图片设置以优化识别效果:根据图片的特点和需求,调整图片的亮度、对比度、清晰度等参数,以提高OCR识别效果。
选择识别语言和输出格式:根据需要识别的文字语言选择合适的识别语言,并设置输出格式,如文本文件、Word文档、Excel表格等。

启动OCR识别过程:点击软件中的识别按钮或者执行相应的命令,启动OCR识别过程,等待软件完成文字提取。
处理批量图片文件:如果需要处理多个图片文件,可以使用软件的批量处理功能,自动识别并提取其中的文字。
手动校正识别错误:对于识别错误或不准确的文字,可以手动进行校正和编辑,确保提取的文字内容准确无误。
应用OCR结果到不同场景:将提取的文字内容应用到不同的场景中,如编辑文档、整理数据、翻译等,以提高工作效率。
调整OCR识别参数以提高准确性:根据需要和实际情况,调整OCR软件的识别参数,以提高准确性和识别效果。
识别多页PDF文件中的文字:对于多页PDF文件,可以使用OCR软件批量识别其中的文字内容,提高处理效率。
使用OCRAPI实现自动化文字提取:如果需要实现自动化文字提取,可以使用OCR软件提供的API接口,实现程序自动调用和文字提取。
注意OCR的局限性和限制条件:OCR技术虽然强大,但仍存在一定的局限性和限制条件,如识别精度受图片质量影响、语言支持有限等。
备份和保存OCR识别结果:对于重要的OCR识别结果,及时进行备份和保存,以免丢失重要信息。
常见问题解答:对于读者常见的问题和疑问,提供解答和解决方案,以帮助读者更好地应用OCR技术。
通过选择合适的OCR软件,进行安装和配置,优化图片设置,选择合适的识别语言和输出格式,手动校正识别错误等一系列步骤,我们可以利用电脑快速提取图片中的文字。这种方法可以大大提高文字提取的效率和准确性,帮助我们更好地处理和利用图片中的文字内容。